RabbitMQ Manager 插件管理统计模块
RabbitMQ Manager 插件在启动的时候 ,会启动一个 rabbit_mgmt_db 进程
这个进程在多个节点中只会有在一个节点上运行.所有节点上的队列信息,节点状态,连接信息,通道信息等都上报到这个进程里进行存储.
HTTP overview ,queues,vhost 等接口都向 这个进程拿信息
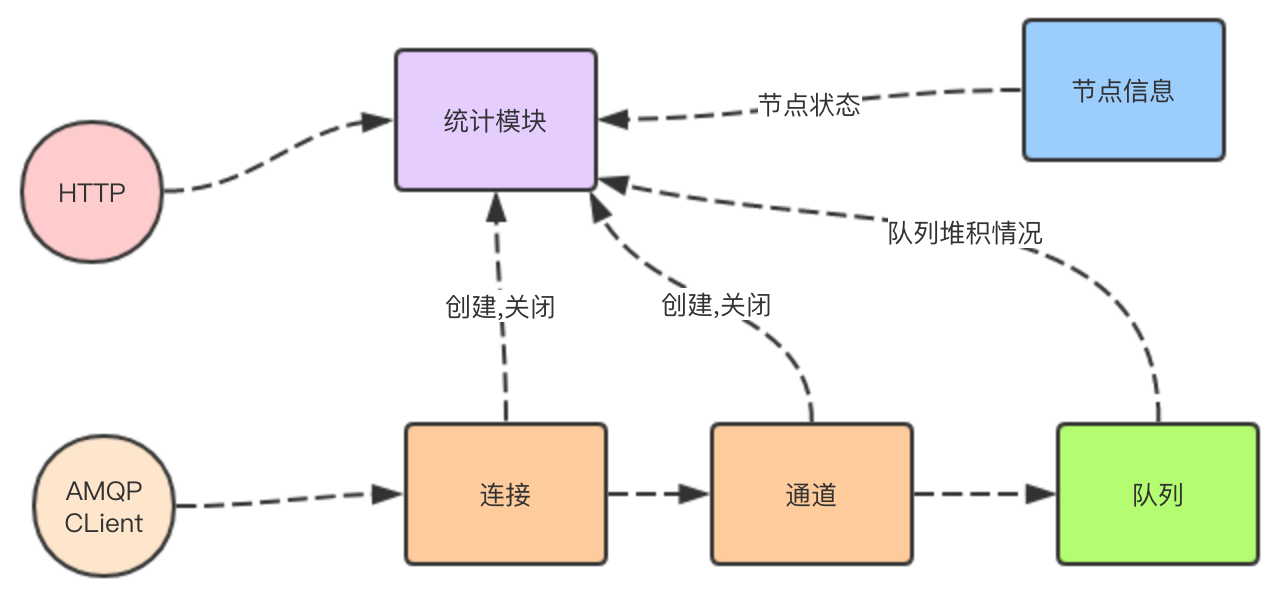
1. 数据上报
所有队列,通道等进队列都要定时的将数据上报给rabbit_mgmt_db 进程。
A. 队列数据上报
1). 设置上报数据的定时器
==每次写入消息或者ack消息等操作的时候都会确保一下定时器是否存活==
"定时发送队列堆积等状态信息给统计模块进程的定时任务 "
只要不存在这个任务就会自动创建. ==定时时间默认为5000ms. == 这个定时时间的值可以个性
参数为:collect_statistics_interval(其他数据上报进程一样)
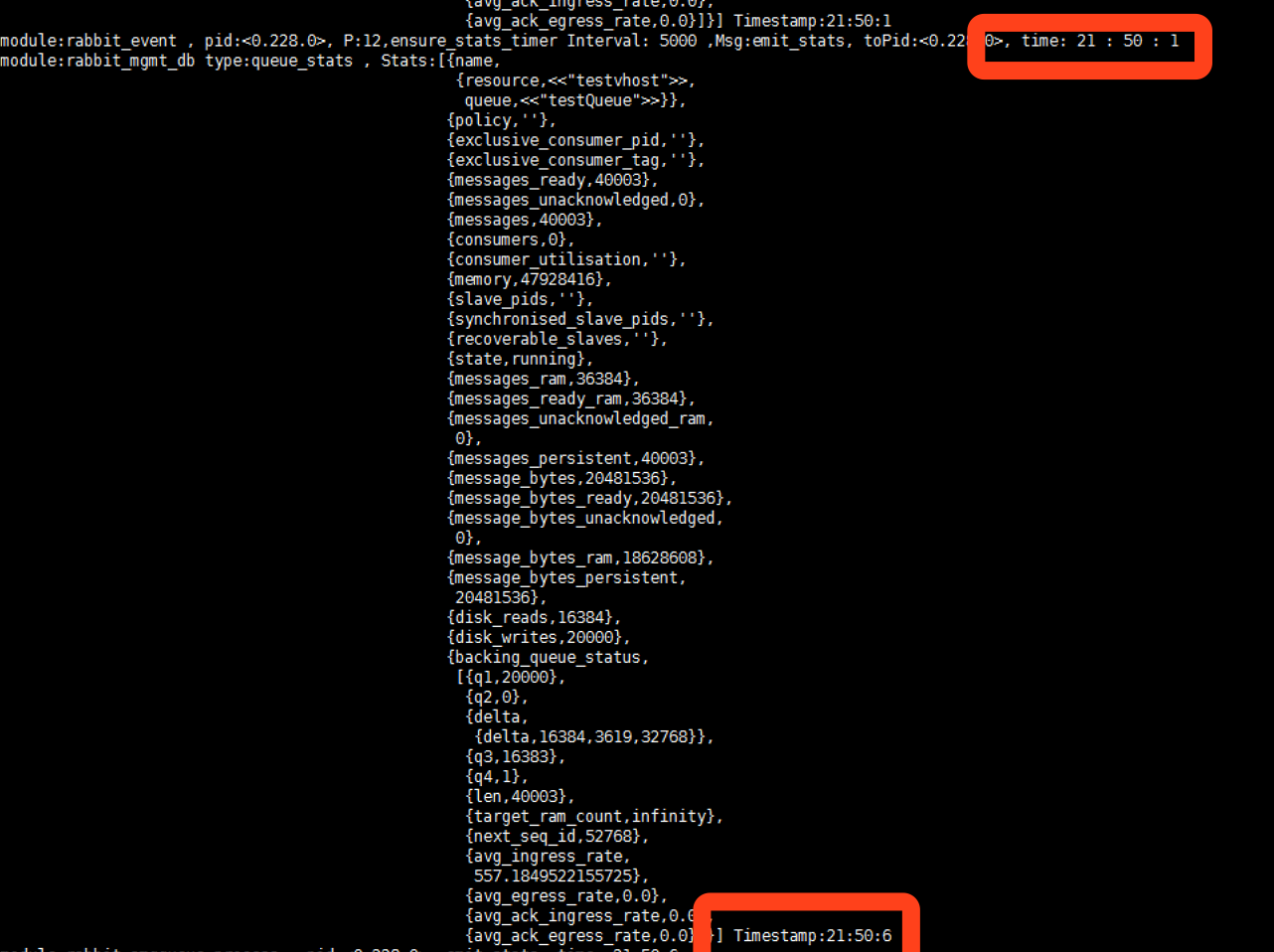
下面是代码 io:format是调试打的日志
ensure_stats_timer(C, P, Msg) ->
case element(P, C) of
#state{level = Level, interval = Interval, timer = undefined} = State
when Level =/= none ->
{ {_, _, _}, {Hour, Minite, Second} } = calendar:local_time(),
io:format("module:~p , pid:~p, P:~p,ensure_stats_timer Interval: ~p ,Msg:~p, toPid:~p, time: ~p : ~p : ~p ~n",[?MODULE,self(),P,Interval,Msg,self(),Hour,Minite,Second]),
TRef = erlang:send_after(Interval, self(), Msg),
setelement(P, C, State#state{timer = TRef});
#state{} ->
C
end.
2). 队列进程在进入状态之前上报数据
假如每次发送的数据比较少,队列进程在进入状态之前,也会进行发送一次状态信息.并且同时清空这个堆积状态上报的定时任务
handle_pre_hibernate(State = #q{backing_queue = BQ,
backing_queue_state = BQS}) ->
{RamDuration, BQS1} = BQ:ram_duration(BQS),
DesiredDuration =
rabbit_memory_monitor:report_ram_duration(self(), RamDuration),
BQS2 = BQ:set_ram_duration_target(DesiredDuration, BQS1),
BQS3 = BQ:handle_pre_hibernate(BQS2),
rabbit_event:if_enabled(
State, #q.stats_timer,
fun () -> emit_stats(State, [{idle_since, now()},
{consumer_utilisation, ''}]) end),
State1 = rabbit_event:stop_stats_timer(State#q{backing_queue_state = BQS3},
#q.stats_timer),
{ {_, _, _}, {Hour, Minite, Second} } = calendar:local_time(),
io:format("module:~p , pid:~p, handle_pre_hibernate emit_stats and stop_stats_timer time: ~p : ~p : ~p ~n",[?MODULE,self(),Hour,Minite,Second]),
{hibernate, stop_rate_timer(State1)}.
3). 定时器上报数据
假如一直有数据生产或者消费等操作,则定时任务5秒后生效,往统计模块发送一条队列状态信息,并清空这一个定时任务.待下一次生产或者ack等操作的时候再创建定时任务
4). 测试:
我们用一个通道往 一个队列里写2万条消息
测试工具: https://github.com/jc3wish/RabbitMQTest
配置文件 [singleSend]
只写
Method=single_send Uri=amqp://guest:guest@127.0.0.1:35673/testvhost ExchangeName=amq.direct RoutingKey=testQueue
写入等待返回多久
WriteTimeOut=10 DeliveryMode=2
写入的数据大小,多个用逗号隔开,随机写入,单位byte
DataSize=512
连接数
ConnectCount=1
每个连接开启多个通道
ChannelCount=1
每个通道总的写入多少条数据
ChanneWriteCount=20000
开启返回confirm模式
WaitConfirm=1
启动: ./RabbitMQTest -c etc/config.ini -key singleSend
RabbitMQ要日志打印信息:

B. 连接信息上报
连接在创建 ,关闭等操作的时候 ,会立即往统计模块发送一次状态信息
在连接成功后,也做个定时任务,5秒发起一个连接状态信息发送给统计模块
连接状态信息包括 连接名称,输入大小,输出大小,连接帐号等基本信息
相关代码:rabbit_reader.erl
C. 通道信息上报
通道和连接一样,在创建 和 关闭的时候,以及 每5秒会上报一次
并且通道进程在休眠之前也会上报一次,连接模块是没休眠的
通道没有输入,输出大小数据的上报
相关代码: rabbit_channel.erl
D. 节点状态信息上报
RabbitMQ Manager插件里的 rabbit_mgmt_external_stats 进行定时5秒上报数据到 rabbit_mgmt_db 进程.
==rabbit_mgmt_external_stats 进程检测和rabbit_node_mointor进程没有直接关系 . rabbit_node_monitor进程是用检测节点是否可用,当节点起来或者宕机的时候会主动往 rabbit_mgmt_db 进程 上次一次数据 .==
==rabbit_mgmt_external_stats 进程主要是定时更新节点信息==
E. 其他数据上报
vhost, queue, exchange 在创建,删除的时候 也会往 rabbit_mgmt_db 进程上报数据.
queue和exchange信息上报的时候 都 会带上vhost名称.
因为在rabbit_mgmt_db 进程数据存储的时候,是以 vhost 为第一维度.
2. 数据存储及读取
不同的数据类型,是存储 在不同的数据表里的,
例如:
- queue_stats
- connection_stats
- channel_stats
- consumers_by_queue
- consumers_by_channel
- node_stats
- node_node_stats
以上表保存的是每个队列的最新,或者节点最新的信息
aggregated_stats 表里存的是 历史信息,用于曲线 展示所用
队列,连接等都是以vhost 做为第一维度进行存储 .
每次overview API去读取信息的时候 ,都是先找到要从哪些vhost读取信息
因为可能不同状态,能访问的vhost可能不一样
每次队列堆积等信息数据上报,都是往 queue_stats 表里追加一条信息.
==但进行读取系统整个堆积曲线的时候 ,是查找出所有vhost,然后进行遍历queue_stats表里的每一个队列的堆积的每一条信息==
每个VHOST的堆积情况在rabbit_mgmt_db 进程里的存储格式如下:
[{messages,
{stats,
{5,
{1548818465000,10,nil,
{1548818470000,0,nil,
{1548818505000,1,nil,
{1548818520000,1,nil,{1548818545000,1,nil,nil} } } } } },
0} },
{messages_ready,
{stats,
{5,
{1548818465000,10,nil,
{1548818470000,0,nil,
{1548818505000,1,nil,
{1548818520000,1,nil,{1548818545000,1,nil,nil} } } } } },
0} },
{messages_unacknowledged,
{stats,
{5,
{1548818465000,0,nil,
{1548818470000,0,nil,
{1548818505000,0,nil,
{1548818520000,0,nil,{1548818545000,0,nil,nil} } } } } },
0} }]:
每次更新队列信息的时候,也会更新VHOST 对应的ETS表里的统计信息
每个VHOST都是按这样的时间戳保存着,并且同一时间点,保存了三条数据
每个队列一样堆积情况也是一样,每个时间戳保存三条数据
其实在rabbit_mgmt_db 进程所有有关历史数据的保存全是按这种时间戳的方式保存
在http API去获取历史数据的时候,比如
以上API 是获取整个集群最近10分钟的数据
==在这个过程中,会遍历vhost对应的ETS表的历史数据,同一时间戳的数据进行累加 然后瑞遍历结果判断是否属于 rates 概念范围的数据进行取样。==
3. 队列堆积数据清除
既然每个队列每次上报一次数据,就往 queue_stats 表里插入一条数据,那数据就会越来越多
==所以 rabbit_mgmt_db 进程在启动的时候,就做一个5000ms 的定时任务, 定时的往 当前进程发送一条内容为"gc"的指令==
这个定时时间在比较低版本的RabbitMQ源码中是不能修改的.
但是gc 策略是可以修改. 和 rates_mode 同级配置。
但是高版本可能已经改掉,在低版本是这样的gc策略。并且这个不要自作 聪明哦,最好不要去修改。 下面是rabbitmq的默认配置
{sample_retention_policies,
%% List of {MaxAgeInSeconds, SampleEveryNSeconds}
[{global, [{605, 5}, {3660, 60}, {29400, 600}, {86400, 1800}]},
{basic, [{605, 5}, {3600, 60}]},
{detailed, [{10, 5}]}]}
]}
- global : 节点信息,VHOST信息 按这个配置进行gc
- basic: 队列,交换机,连接,通道 信息按 这个配置进行gc
- detailed: 其他信息按 这个配置进行gc,
每条信息都和相对应的gc策略的配置进行对比,{x,y}的配置 Now-TS <= X * 1000的情况下进行保存,或者进行数据合并。否则进行删除。
比如队列信息,第一次策略605,5 的配置,第一次遍历可能是合并到下条数据,但是经过86400 之后,也就是1天,就不会再合并了,只会有删除。
这也就是为什么管理界面上最大只能查看到最近一天的数据了
相关代码如下:
set_gc_timer(State) ->
TRef = erlang:send_after(?GC_INTERVAL, self(), gc),
State#state{gc_timer = TRef}.
handle_info(gc, State) ->
noreply(set_gc_timer(gc_batch(State)));
gc_batch(State = #state{aggregated_stats = ETS}) ->
{ok, Policies} = application:get_env(
rabbitmq_management, sample_retention_policies),
Rows = erlang:max(?GC_MIN_ROWS,
round(?GC_MIN_RATIO * ets:info(ETS, size))),
gc_batch(Rows, Policies, State).
gc_batch(0, _Policies, State) ->
State;
gc_batch(Rows, Policies, State = #state{aggregated_stats = ETS,
gc_next_key = Key0}) ->
Key = case Key0 of
undefined -> ets:first(ETS);
_ -> ets:next(ETS, Key0)
end,
Key1 = case Key of
'$end_of_table' -> undefined;
_ -> Now = floor(os:timestamp(), State),
Stats = ets:lookup_element(ETS, Key, 2),
gc(Key, Stats, Policies, Now, ETS),
Key
end,
gc_batch(Rows - 1, Policies, State#state{gc_next_key = Key1}).
gc({ { Type, Id }, Key}, Stats, Policies, Now, ETS) ->
Policy = pget(retention_policy(Type), Policies),
case rabbit_mgmt_stats:gc({Policy, Now}, Stats) of
Stats -> ok;
Stats2 -> ets:insert(ETS, { { { Type, Id }, Key}, Stats2})
end.
4. statistics_db_event_queue
在RabbitMQ Manager插件管理界面首页里,可能会出现 警告
The management statistics database currently has a queue of xx events to process. If this number keeps increasing, so will the memory used by the management plugin. You may find it useful to set the rates_mode config item to none.
这个警告里的 xx 值就是 overview api 里获取返回的 statistics_db_event_queue 值.
当这个值大于1000的时候 会进行在界面上显示出来.
这个值是表示 ==rabbit_mgmt_db 进程里待处理其他进程发送过来的数据的队列长度.==
包括队列, 通道,连接及节点状态等进程上报数据给 rabbit_mgmt_db 的上报数据以及 API请求数据.
但这里并不包括 "gc"命令
比如每次队列上次一数据队列长度就会 + 1
HTTP api 调用/api/overview接口,或者调用/api/queues 接口的时候 ,队列长度也会 +1
当然每次处理完一个请求 队列长度 就会 -1
这个队列长度是由erlang本身统计的. 并不是由RabbitMQ业务代码实现的.
%% We want timely replies to queries even when overloaded, so return 5
%% as priority. Also we only have access to the queue length here, not
%% in handle_call/3, so stash it in the dictionary. This is a bit ugly
%% but better than fiddling with gen_server2 even more.
prioritise_call(_Msg, _From, Len, _State) ->
put(last_queue_length, Len),
prioritise_call 是当erlang里采用gen-server 调用时候,会进行回调这个函数.并返回当前信息的权重大小.这里返回的权重大小是返回的值越大,权重越高.
我们上面也说了 队列堆积信息存储是按时间戳一条一条存储的.
在读取的时候进行遍历过滤.
再靠gc指令将不要的数据进行清除.
假如我们有大量队列的数据都在写入或者连接瞬间重连很多的情况的情况下,
rabbit_mgmt_db 进程里的存储的数据也越来越多,并且 等待 rabbit_mgmt_db 进程处理的队列信息也变得越来越多
这样就会造成 rabbit_mgmt_db 进程所在节点内存爆涨.
造成管理界面访问不了,API访问不了, 严重则造成宕机等情况
所以==做好 statistics_db_event_queue 值的监控很有必要.==
但这里要注意一下,这个地方监控还是依懒http接口.所以在做这个监控的时候要注意把握一个度
如果 statistics_db_event_queue 很大的,影响了服务的情况下,需要手工在把 rabbit_mgmt_db 这个进程给干掉,让这个进程重启一下.
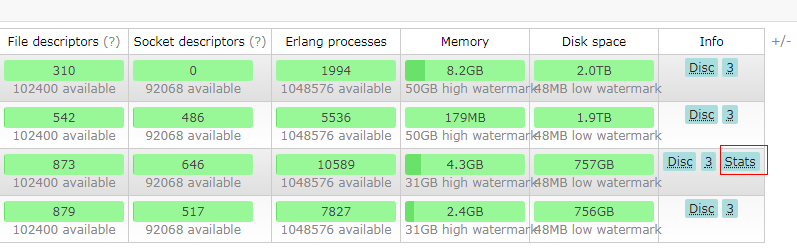
如果是是集群的话,得去 带有 Stats 标识的结点上运行下面的命令
3.6.2以前的版本:
rabbitmqctl eval 'exit(erlang:whereis(rabbit_mgmt_db), please_terminate).'
3.6.2,3.6.2以后的版本:
rabbitmqctl eval 'supervisor2:terminate_child(rabbit_mgmt_sup_sup, rabbit_mgmt_sup),rabbit_mgmt_sup_sup:start_child().'
小结
RabbitMQ 在低版本中,rabbitmq manager 管理插件开启后,整个集群的性能和 管理插件里的rabbit_mgmt_db 进程有相关大关系。
并不是节点越多,性能越强,也受这个管理进程影响。
同时如果短连接非常多,管理节点压力也会变大。可能会影响自己的监控进程去抓去HTTP API的数据,甚至造成管理节点内存爆涨问题。
需要对 statistics_db_event_queue 做好监控操作。